
If you’re looking for a fair review of the Bright Data Scraping Browser, you’ve come to the correct source. Businesses and academics alike rely heavily on public data scraping ethically to mine the internet for relevant information.
When working with complicated websites that use bot-detection systems and website bans, this may be an especially difficult and time-consuming operation.
The Bright Data Scraping Browser is a specialized automated web browser made for gathering information. In this piece, we’ll discuss why Bright Data Scraping Browser is a useful tool for data extraction tasks, as well as evaluate its main features and advantages.
This Bright Data scraping browser review will assist you, whether you run a little company or a multinational corporation.
After reading this review, you can decide whether Bright Data Scraping Browser is the best option for your data scraping requirements.
- About Bright Data Scraping Browser
- Top-Rated Scraping Browser – 3 in 1 Tool
- 🔥 Features At A Glance🔥
- Why Use Bright Data Scraping Browser?
- How does scraping Browser works?
- What makes Scraping Browser Superior to Headless Browsers?
- 🏷️ Bright Data Scraping Browser Pricing & Sign-Up Steps
- Bright Data Automated Browser Pros and Cons
- Also, Read:
- FAQS
- Conclusion: Is It Worth The Price?
About Bright Data Scraping Browser
One of Bright Data’s recently released products is the Scraping Browser. This utility was built to facilitate web scraping by giving users access to a proxy infrastructure and a foolproof unblocking mechanism.
Its purpose is to streamline the process of gathering information from dynamic web pages.
Top-Rated Scraping Browser – 3 in 1 Tool
🌐 Web Scraping
You can tell this is a web scraping program just by looking at the name. But how well does it scrape websites, and what qualities make it so effective at this task? This browser may be used inside Puppeteer and Playwright with the help of an argument.
Playwright and Puppeteer are supported out of the box. Since it utilizes Bright Data’s proxy network and web unblocker, no extra proxies need to be set up. The geo-targeting feature allows for regionally specific web scraping.
⚙️ Browser Automation
This browser may have been designed with site scraping in mind, but it’s also great for automating any number of other browser-based activities. It may be used to do a wide variety of automated operations, including scrolling, clicking buttons, entering text into input fields, loading whole web pages, and more.
These, together with its ability to bypass blocks, make it an ideal browser for scripting common activities. This may be accomplished with the help of the Scraping Browser and the Puppeteer and Playwright API.
⛔ Unblocking Infrastructure
The ability to bypass filters is what sets Scraping Browser apart. Websites often do not allow automatic access; therefore browsers often restrict automated access.
The effectiveness and sophistication of anti-spam systems of websites mean that even the most fundamental unblocking procedures are rendered useless.
There are clubs with in-house unblocking tools. If you don’t have one and don’t want to get one just for Scraping Browser, then you’re in luck.
🔥 Features At A Glance🔥

The Bright Data Scraping Browser is a specialized web browser built with automation and simplification for data scraping in mind. Because of its many benefits, it is a great tool for data scraping projects.
The Bright Data Scraping Browser is a single-browser solution that will help you save time, money, and other valuable resources.
- Two key technologies: A web unblocker and a proxy network form the foundation of the Scraping Browser.
- Bright Data’s proxy network is comprised of IPs from all over the globe, allowing for localized data scraping to be supported.
- The dynamic and efficient web unblocker bypasses firewalls and anti-spam software with ease.
- Bandwidth and session usage-based pricing show that its services are reasonably priced.
- Works straight out of the box with both Puppeteer and Playwright. Using Puppeteer or Playwright, it’s very simple to transfer your existing automation workflow to Scraping Browser.
- Extremely scalable; can support an unlimited number of concurrent browser sessions.
- A very quick and efficient solution that guarantees you a high level of availability, making it suitable for mission-critical software.
Why Use Bright Data Scraping Browser?
💰 It Conserves Time and Money:

The Scraping Browser frees developers from the burden of rolling their infrastructure or relying on unreliable third-party services. The browser is preconfigured for data scraping, making it an efficient and cost-effective resource.
🚀 Perfect for scaling:

Scalability is a major advantage of adopting Bright Data Scraping Browser. The browser can manage thousands of concurrent sessions when it is hosted on the Bright Data server.
This makes it ideal for data scraping initiatives that aim to collect information from a large number of web pages simultaneously.
The Scraping Browser is capable of managing many sessions, making it an efficient tool for gathering data from a wide variety of websites simultaneously.
🔓 Unblocks sites for you:

One of the trickiest aspects of data scraping is finding ways past security measures put in place on websites. The Bright Data Scraping Browser can quickly adapt to new barriers like CAPTCHAs, fingerprint verification, and retries, all while maintaining its human-like appearance.
The Scraping Browser removes the need for programmers to manually unblock sites or pay for premium unblocking services.
😊 Compatible with Puppeteer:

The Bright Data Scraping Browser is compatible with the well-known API for automation, Puppeteer, making it easier to scrape data.
This means that the Scraping Browser can bypass even the most stringent scripts and site filters that hunt for bots, making it superior to empty and automated browsers.
With Puppeteer, programmers have greater leeway and authority over the browser’s behavior. The quality and reliability of data scraping are both improved by this.
How does scraping Browser works?

Bright Data’s Scraping Browser is a functional platform with a deceptively simple concept on the surface. However, there is a fair amount of intricacy behind the hood.
The essential gist is that it facilitates the removal of obstacles during web scraping. That begs the question, though: how exactly does it function?
You may think of Scraping Browser as a proxy in disguise. It functions as a browser and is built immediately into Puppeteer and Playwright. When a web request is sent, however, the program processes it and deals with any obstacles it encounters.
It was established early on that the Bright Data proxy and web unblocking infrastructure is used by the Scraping Browser, an automated browser. These two features are what give Scraping Browser its true strength.
With its support, you can forget about dealing with obstacles like proxies, captchas, and headers and concentrate only on the steps to follow to access the necessary data.
What makes Scraping Browser Superior to Headless Browsers?

Developers should know the distinctions between a headless browser and a “headfull”/GUI browser before deciding on an automated browser. Without a graphical user interface, a browser is known as a “headless browser.”
When scraping huge amounts of data, using proxies and headless browsers may be inefficient since bot-protection software can quickly identify the browsers as bots.
In comparison to headless browsers, Scraping Browser makes it easier to scale data scraping projects and get over roadblocks. Scraping Browser is a graphical user interface browser (also known as a “headfull” browser) that can be managed using Puppeteer or Playwright API.
Bot detection systems are less likely to flag a browser with a graphical user interface. The built-in website unlocking features of Scraping Browser take care of restrictions mechanically.
Because Scraping Browsers are hosted on Bright Data’s servers, you may open as many as you need without requiring a massive in-house IT infrastructure, making them perfect for scaling online data scraping initiatives.
🏷️ Bright Data Scraping Browser Pricing & Sign-Up Steps
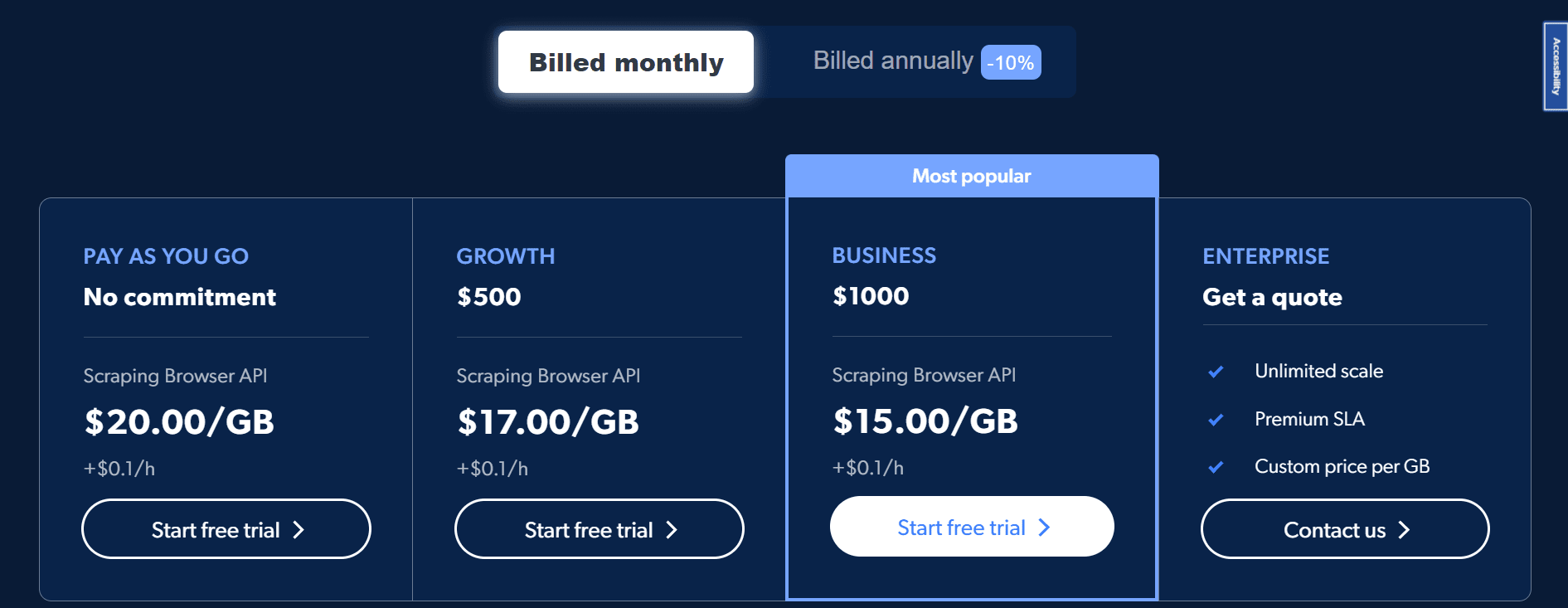
The cost of using the Bright Data Scraping Browser is reasonable for enterprises of all sizes. The firm offers four alternative price tiers—Pay As You Go, Growth, Business, and Enterprise—to accommodate a wide variety of customers.
People who only need to scrape infrequently or in tiny quantities might benefit from the Pay As You Go option. It’s a plan that requires no long-term commitment and charges you just for what you use. You’ll pay $20.00 per GB plus $0.01 per hour with this plan.
If your company needs to scrape larger and larger volumes of data, the Growth plan is for you. It’s $500 a month, but it’s 10% cheaper than Pay As You Go. The rate for this package is $17.00 per GB + $0.1 per hour.
The Business plan is the most well-liked option since it caters specifically to businesses looking to expand their data scraping operations. The monthly fee is $1000, which is a 25% discount from the Pay As You Go option. The rate for this package is $15.00 per GB plus $0.1 per hour.
Finally, the Enterprise plan is tailor-made for scalable enterprises that value service level agreements (SLAs). The cost of this strategy is customized to meet your specific requirements and preferences. This includes a personal account manager, per-GB price adjustments, and around-the-clock assistance.
In addition, if you pay yearly, you may save up to 10%!
Let’s see how you can sign up and use the Bright Data scraping browser.
Sign Up Steps
Step 1: Visit the official website of Bright Data Scraping Browser and click on the pricing section.
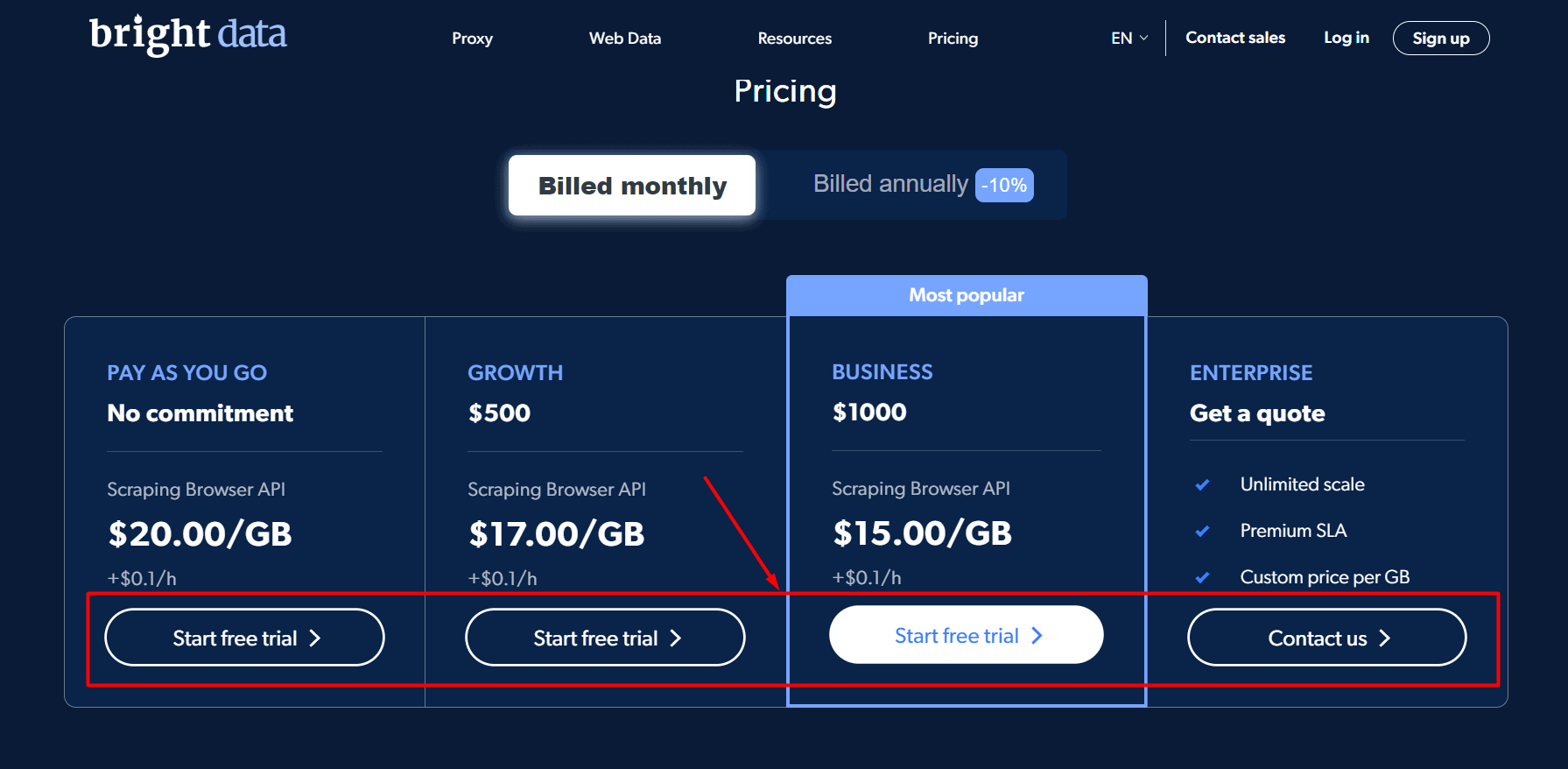
Step 2: Since you are using it for the first time, you need to sign up with your name and email address.
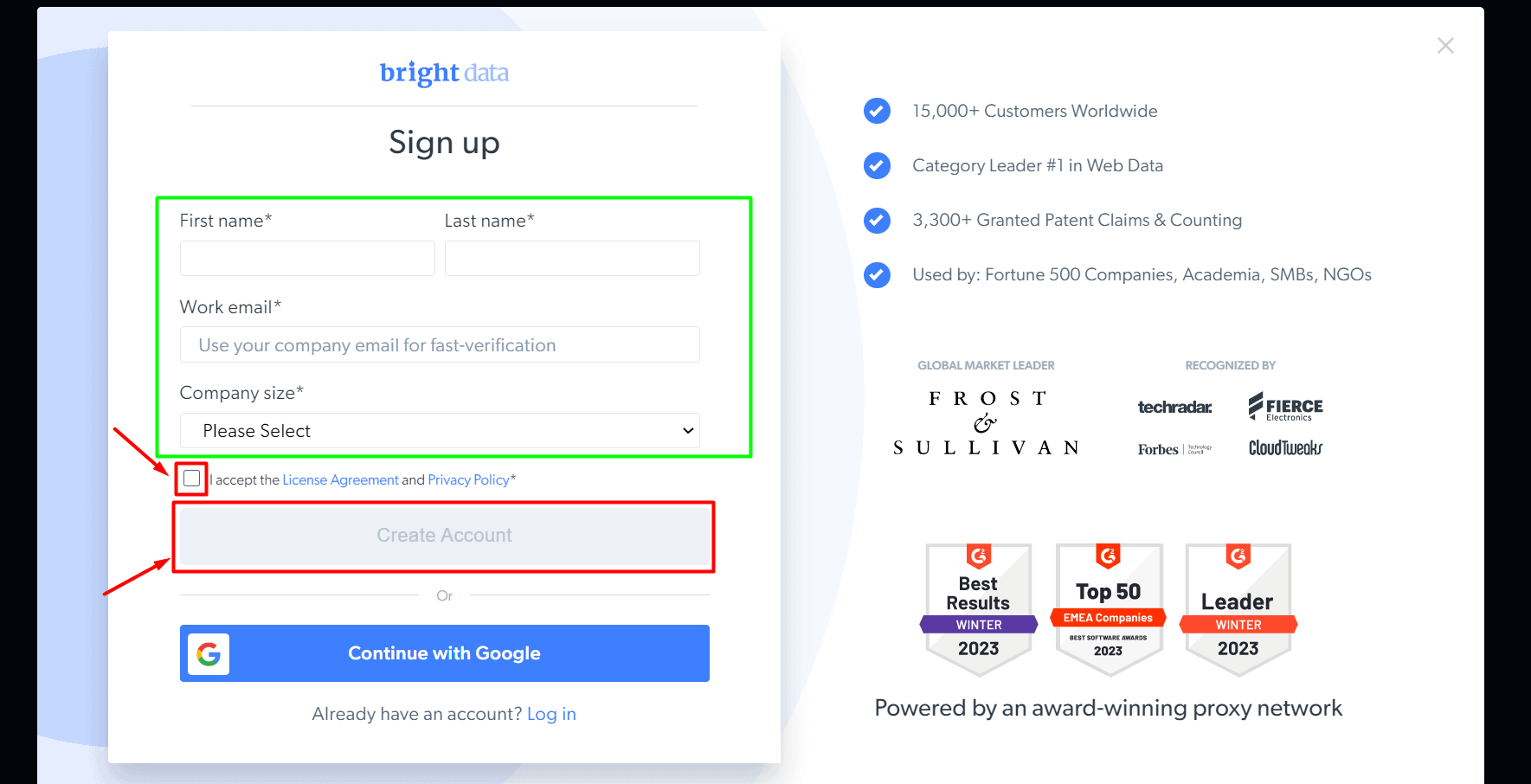
Step 3: Set up your password, and you can sign into the Bright Data browser.
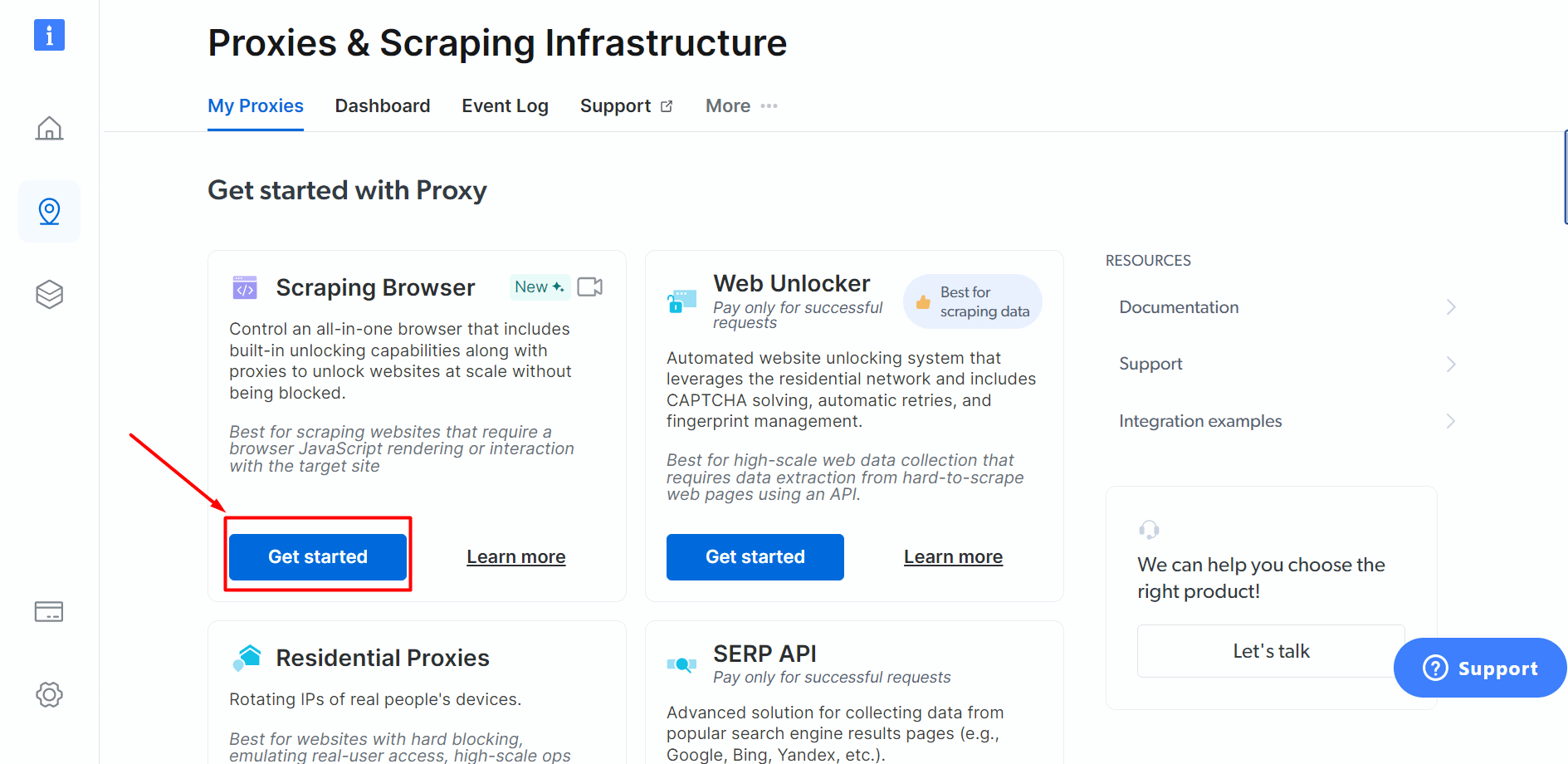
Step 4: Once you sign in, you need to go to My Proxies and click on Get Started. You will then check the estimated costs. Review the same and activate your plan.
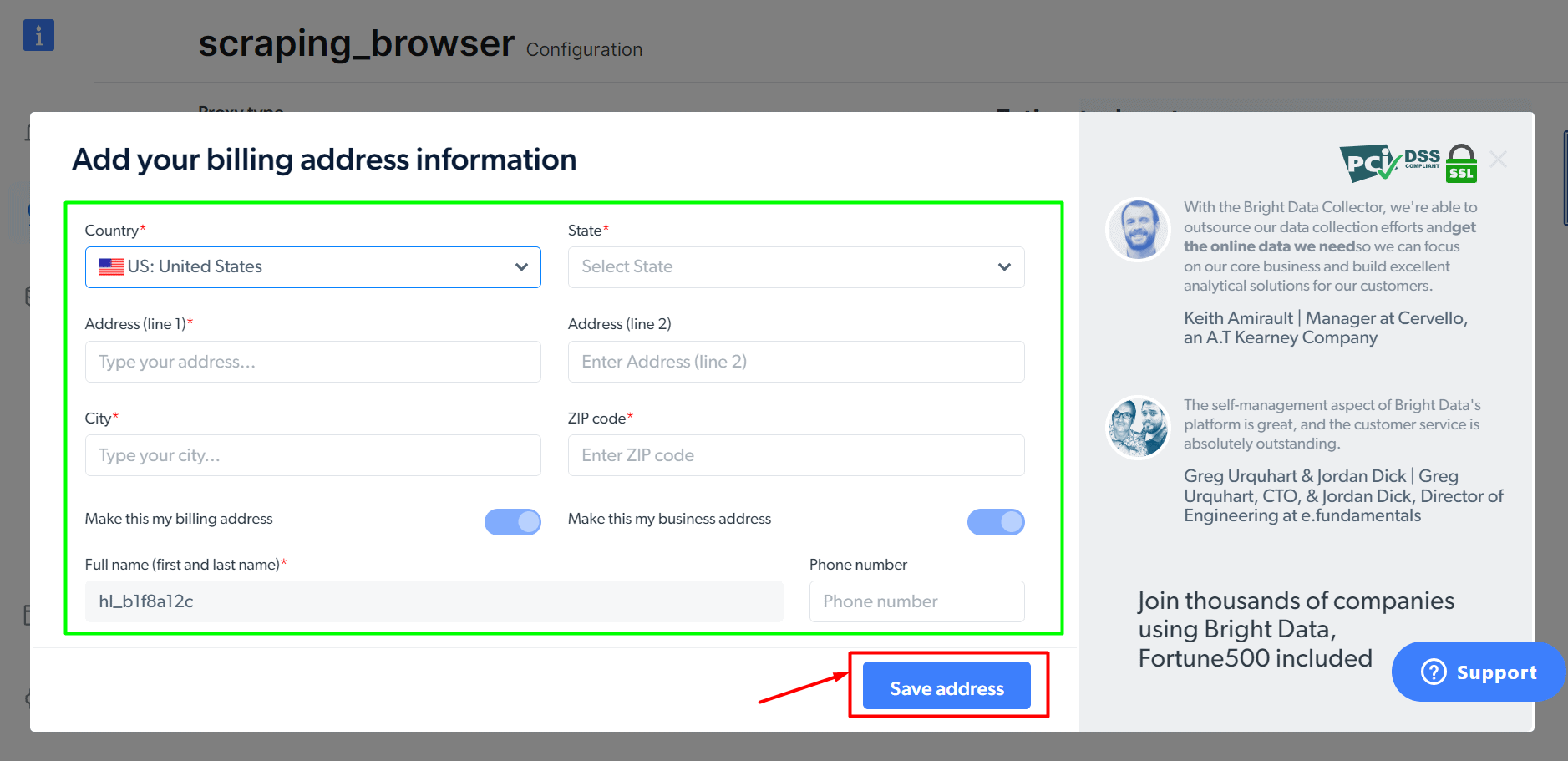
Step 5: Fill up the address details and save them. You can then proceed with the payment.
Once your payment is successful, you are good to go.
Bright Data Automated Browser Pros and Cons
👍 PROS
- Flexible pricing plans.
- A fast-speed reliable network for working with data.
- Simple and efficient to use.
- Easy to set up.
- Operational support.
- Dedicated customer support.
- Huge variety of options and customized setups for proxy service needs.
- Works stably without any interruptions.
👎 CONS
- Certainly not the cheapest service around.
Also, Read:
- List Of 5 Best Cheap Residential Proxies Under $10- Maximum Performance And Reliability
- Top Residential Proxies Providers in 2023
FAQS
What makes Scraping Browser superior to other web scraping tools like Headless Chrome and Selenium written in Python?
Automatic website blocking is handled via Scraping Browser’s built-in website unlocking capability. Because the Scraping Browsers are opened on Bright Data’s servers and include automatic unlocking, they are well suited for growing online data scraping operations without needing substantial infrastructure.
When would I need to scrape in a browser?
Data scraping is done by automated browsers if developers need JavaScript rendering of a web page or interactive features (hovering, clicking, changing pages, screenshots, etc.). In addition, when numerous sites need to be scraped for data at once, browsers are helpful.
How does Scraping Browser differ from other Bright Data proxy solutions, and when should I use it?
The power of Web Unlocker’s automatic unlocking capabilities is included in Scraping Browser, an automated browser optimized for data scraping. In contrast to Web Unlocker, which only supports single-step queries, Scraping Browser allows developers to interact with websites to harvest information. Additionally, it is perfect for data scraping projects that require the use of multiple browsers, scalability, and automatic administration of website unblocking activities.
Conclusion: Is It Worth The Price?
The Bright Data Scraping Browser is an effective data scraping tool that provides several advantages and features to facilitate your scraping tasks.
This browser may save you time and effort while attaining greater website unlocking success rates than proxies because of its efficient website unblocking features, compatibility with Puppeteer and Playwright, scalability, and artificial intelligence technology.
Its capacity for automatically unlocking websites also makes it a useful instrument for large-scale scraping projects that need sophisticated unlocking procedures.
No matter the size of your company, Bright Data Scraping Browser is an effective solution for automating your data scraping processes and gleaning insights from the web.